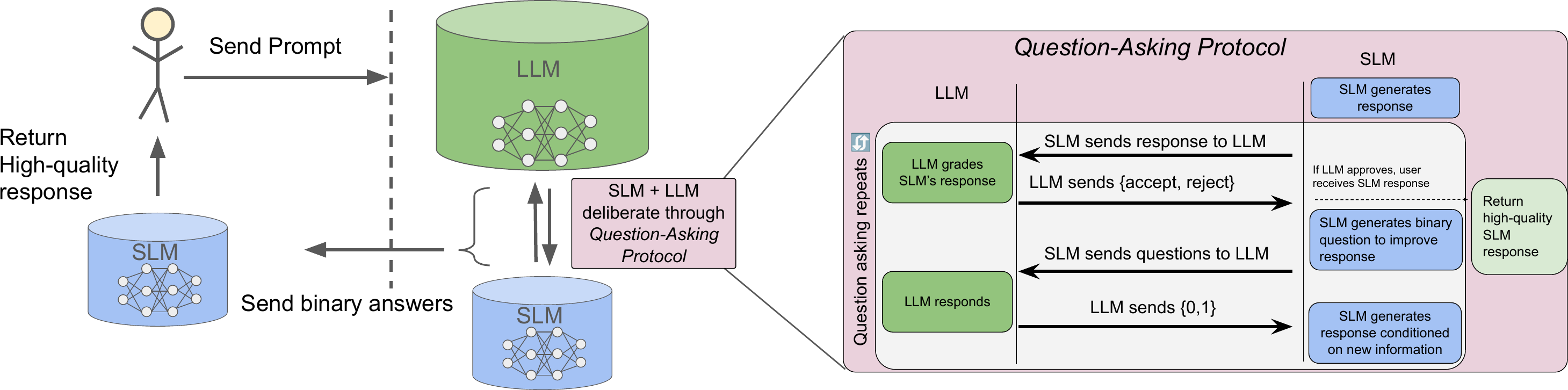
Question-Asking Compression
Can a small model match a large model's answer using only 10 yes/no questions (10 bits)?
From the paper Haiku to Opus in Just 10 Bits: LLMs Unlock Large Compression Gains
Roy Rinberg, Annabelle Michael Carrell, Simon Henniger, Nicholas Carlini, Keri Warr
How It Works
Inspired by 20 Questions, QA compression turns model knowledge transfer into an interactive game. The small model identifies its own uncertainty, asks targeted questions, and uses the answers to self-correct. Only the binary answers travel over the wire.
Step 1 Initial Attempt (Small Model)
The small model attempts to solve the problem on its own, producing an initial answer that may contain errors or gaps.
Step 2 Generate Questions (Small Model)
The small model examines its own solution and formulates targeted yes/no questions about it: "Is my approach to step 3 correct?", "Did I apply the tax rate to the right subtotal?"
Step 3 Binary Answers (Large Model)
The large model answers each question with a single yes or no. Each response is exactly 1 bit of information. 10 questions = 10 bits total.
Step 4 Revised Answer (Small Model)
The small model incorporates all 10 answers and produces a revised solution. Because the questions are deterministic given the initial response, only the 10-bit answer string needs to be transmitted.
Your key is stored only in your browser's local storage. We do not store or log your API key or queries on the server — it is passed through to OpenRouter and discarded.